Contributions

Our main contributions are summarized as follows:
- Theoretical Framework: We establish a novel theoretical framework that formalizes autoregressive token generation in MLLMs through the lens of concept drift theory, enabling systematic identification and causal analysis of detrimental reasoning divergence during non-stationary reinforced custom-tuning.
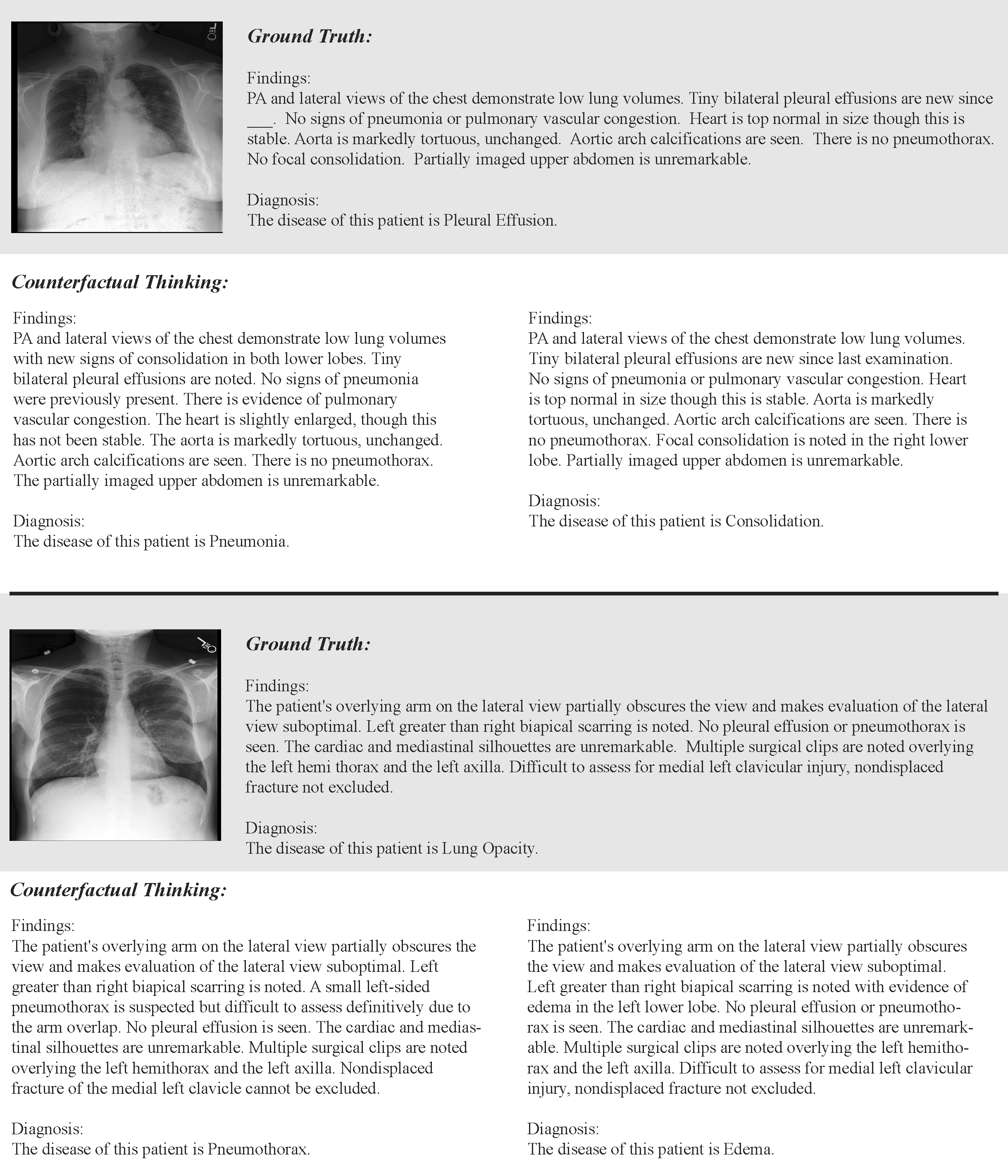
- Counterfactual Preference Optimization (CPO): We propose CPO, which synergizes structured domain-specific knowledge with systematic counterfactual intervention, driving the MLLMs with preference-aligned reinforcement learning. By embedding learnable concept graphs as the expert and generating adversarially-constrained reasoning trajectories, our approach achieves substantial decoupling between beneficial distribution adaptation and detrimental concept drift.
- Empirical Validation: We conduct comprehensive empirical validation across various clinical benchmarks for chest radiograph, including disease classification, diagnostic report generation and zero-shot generalization. The superior results demonstrate statistically significant improvements in robustness, generalization, and accuracy under non-stationary custom-tuning.
- CXR-CounterFact (CCF) Dataset: As a pioneer contribution to the community, we introduce CCF, a large-scale dataset comprising 320,416 meticulously curated counterfactual reasoning trajectories derived from MIMIC-CXR.