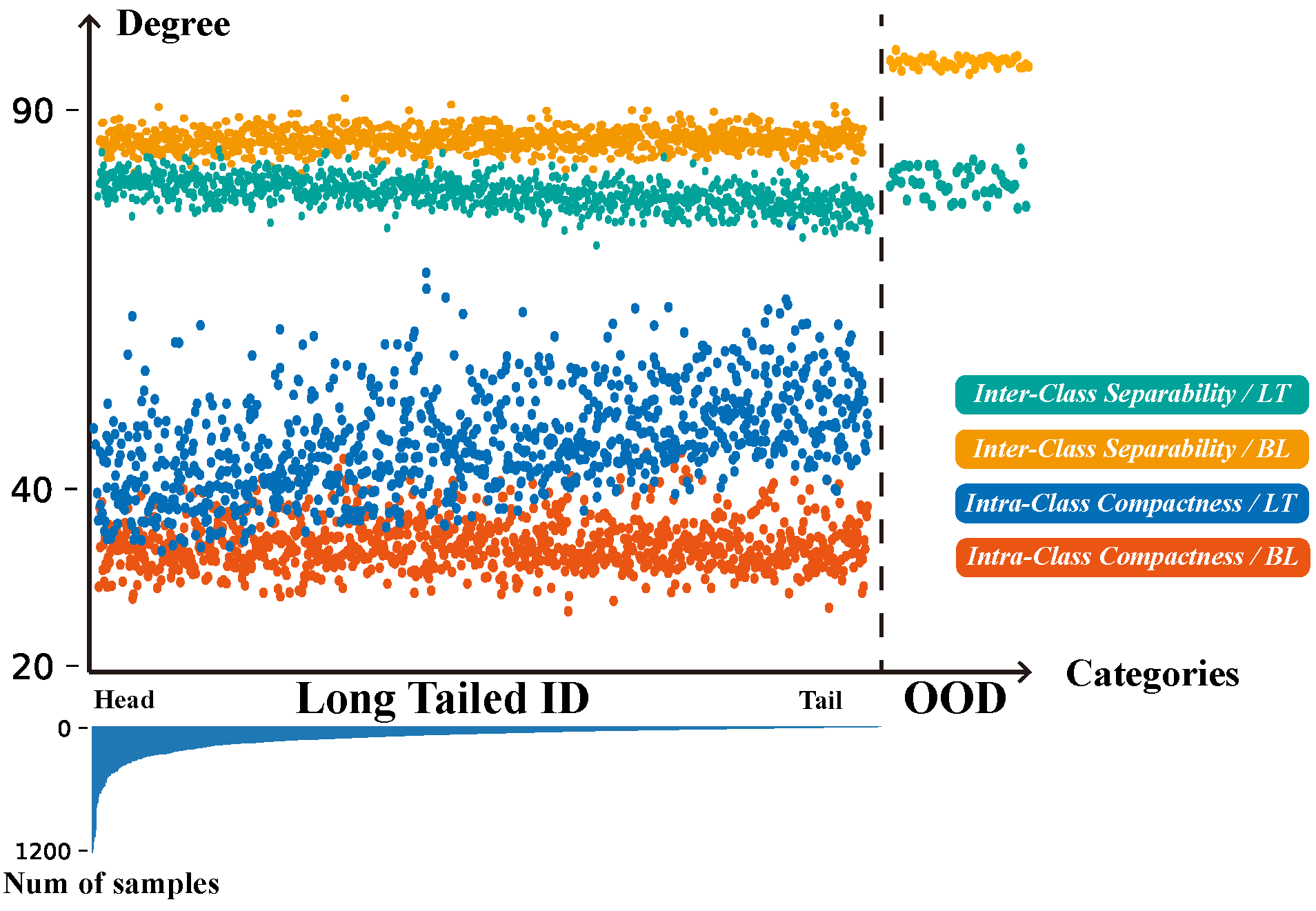
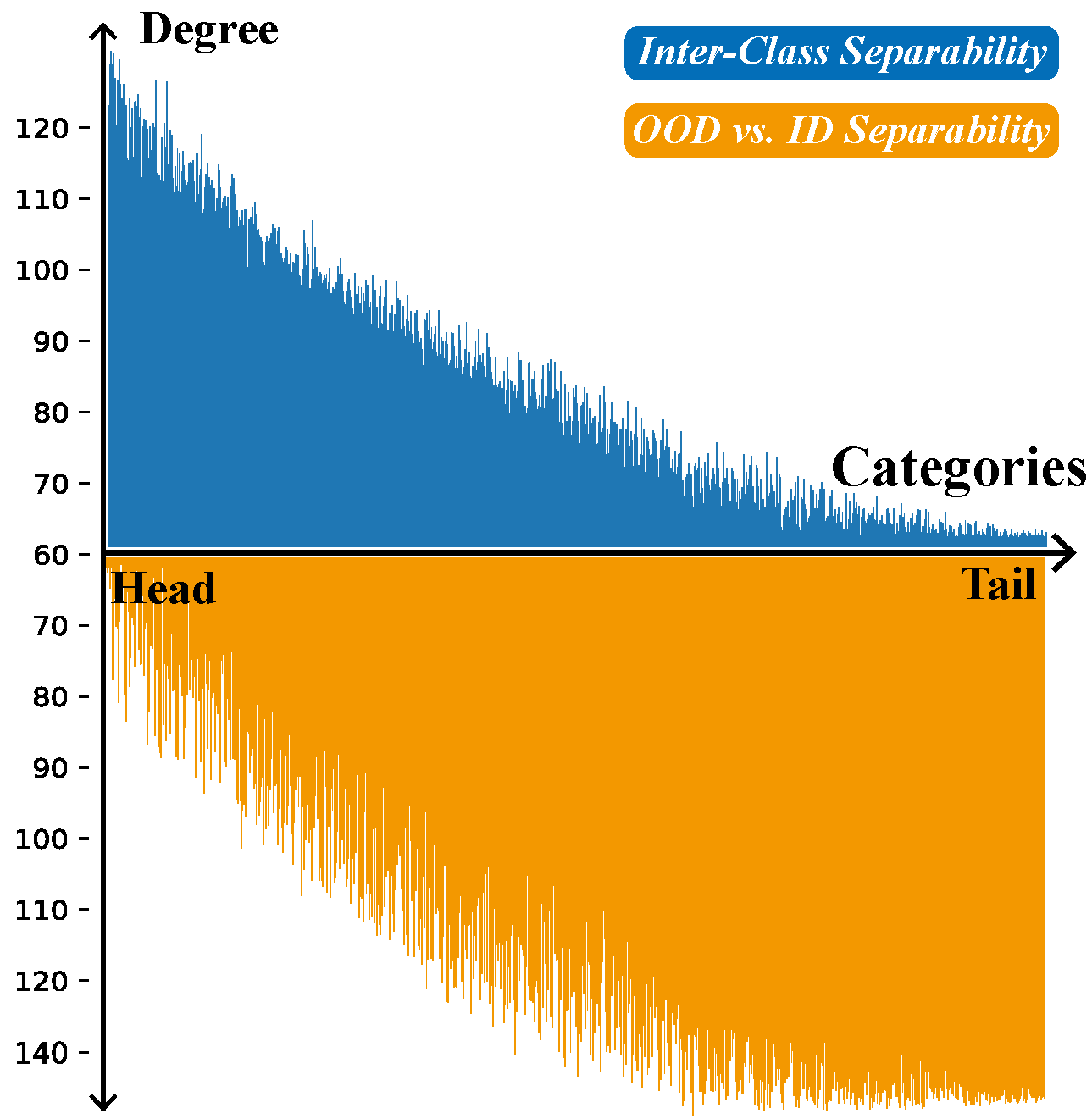
- Uncovering Pre-training Bias: We are the pioneers in revealing the unexplored impacts of concept drift to multi-modal large language models, especially in the image-text alignment in the pre-training and feature space allocation in the fine-tuning.
- Unified Concept Drift Framework: The concept drift theory is introduced and extended to multi-modal data. The novel T-distributed spherical adapter is proposed to perform tailed adaptation and OOD detection simultaneously.
- Superior Generalization & Robustness: In downstream tasks (long-tailed classification, OOD detection), ours demonstrates statistically significant improvements over competitive fundamental models (e.g. CLIP).
- OpenMMlo Dataset: We engineered a large-scale multi-modal long-tailed open-world dataset (OpenMMlo) composed of ~740,000 imbalanced image-caption pairs annotated for real-world scenarios.
Abstract
Multi-modal Large Language Models (MLLMs) frequently face challenges from concept drift when
dealing with real-world streaming data, wherein distributions change unpredictably. This mainly
includes gradual drift due to long-tailed data and sudden drift from Out-Of-Distribution (OOD)
data, both of which have increasingly drawn the attention of the research community. While these
issues have been extensively studied in the individual domain of vision or language, their
impacts on MLLMs in concept drift settings remain largely underexplored.
In this paper, we reveal the susceptibility and vulnerability of Vision-Language (VL) models to significant biases arising from gradual drift and sudden drift, particularly in the pre-training. To effectively address these challenges, we propose a unified framework that extends concept drift theory to the multi-modal domain, enhancing the adaptability of the VL model to unpredictable distribution changes.
Additionally, a T-distribution based drift adapter is proposed to effectively mitigate the bias induced by the gradual drift, which also facilitates the model in distinguishing sudden distribution changes through explicit distribution modeling. Extensive experiments demonstrate our method enhances the efficiency and accuracy of image-text alignment in the pre-training of VL models, particularly in the concept drift scenario.
In this paper, we reveal the susceptibility and vulnerability of Vision-Language (VL) models to significant biases arising from gradual drift and sudden drift, particularly in the pre-training. To effectively address these challenges, we propose a unified framework that extends concept drift theory to the multi-modal domain, enhancing the adaptability of the VL model to unpredictable distribution changes.
Additionally, a T-distribution based drift adapter is proposed to effectively mitigate the bias induced by the gradual drift, which also facilitates the model in distinguishing sudden distribution changes through explicit distribution modeling. Extensive experiments demonstrate our method enhances the efficiency and accuracy of image-text alignment in the pre-training of VL models, particularly in the concept drift scenario.



